Introduction to the Graph Algorithms
We use various types of Data Structures according to the need we have. We are going to discuss Graphs and the way of optimizing the graphs as required for our problem definitions.
What is a Graph?
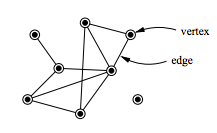
Graphs are widely used nowadays. They are used in economics, aviation, physics, biology (for DNA analysis), mathematics, and other fields. A graph is a non-linear Data Structure with nodes(vertices) and edges in Computer Science that is used to implement the undirected graph as well as directed graph theories from the domain of graph theory within Mathematics.
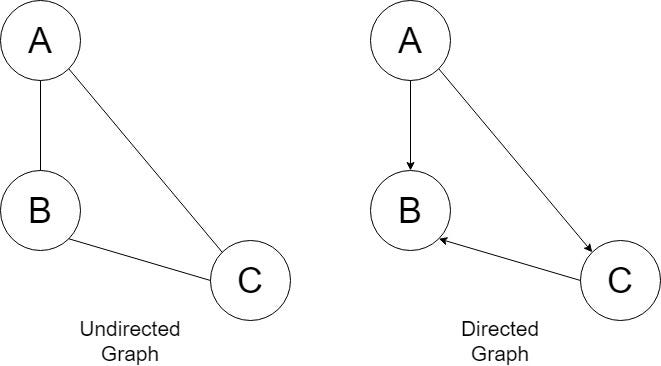
There are two types of Graphs that are needed to this level.
- Directed graph
- undirected graph
Graph Algorithms
One of the crucial operations that can be performed on graphs is traversing or searching. There are several algorithms that work on the Graphs. Such as
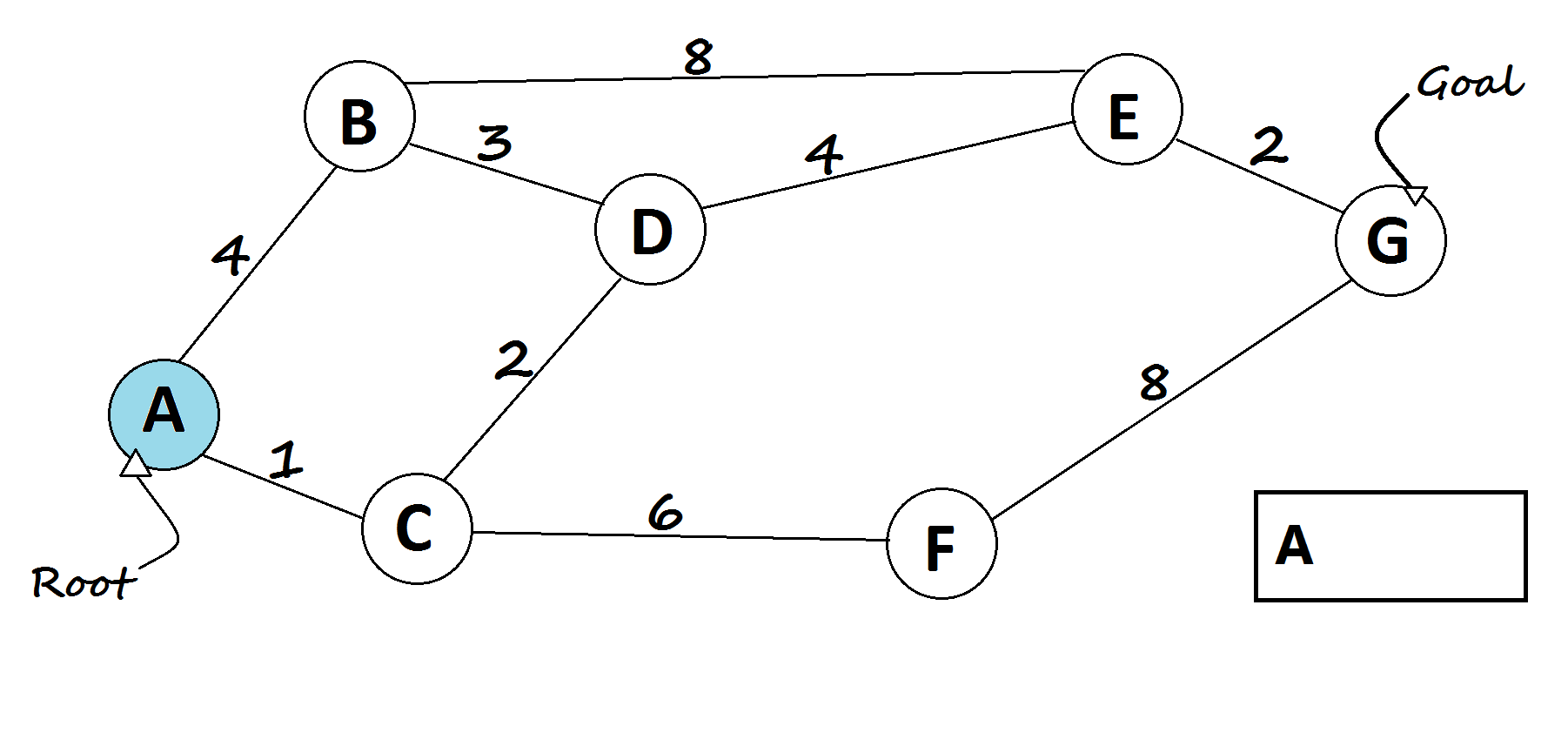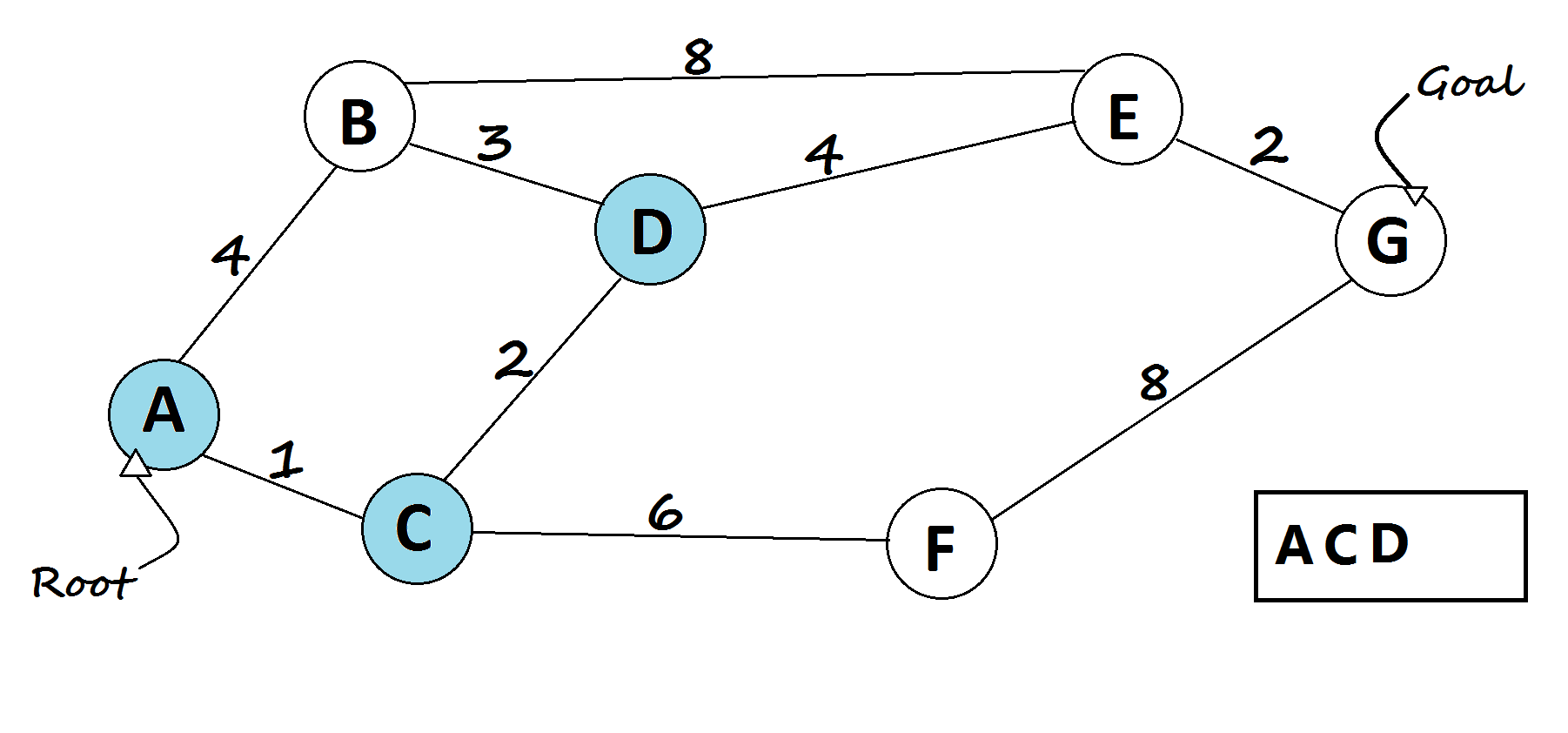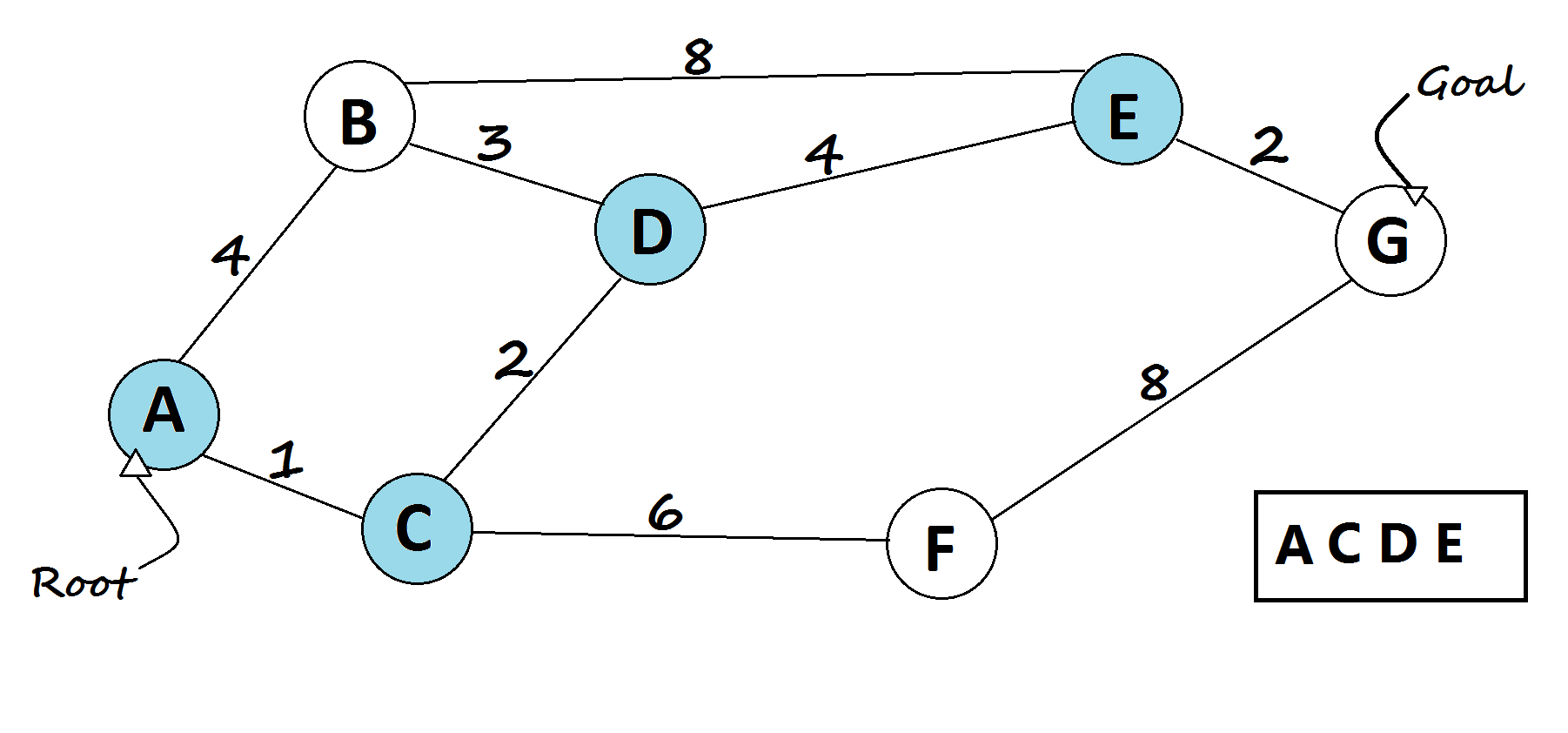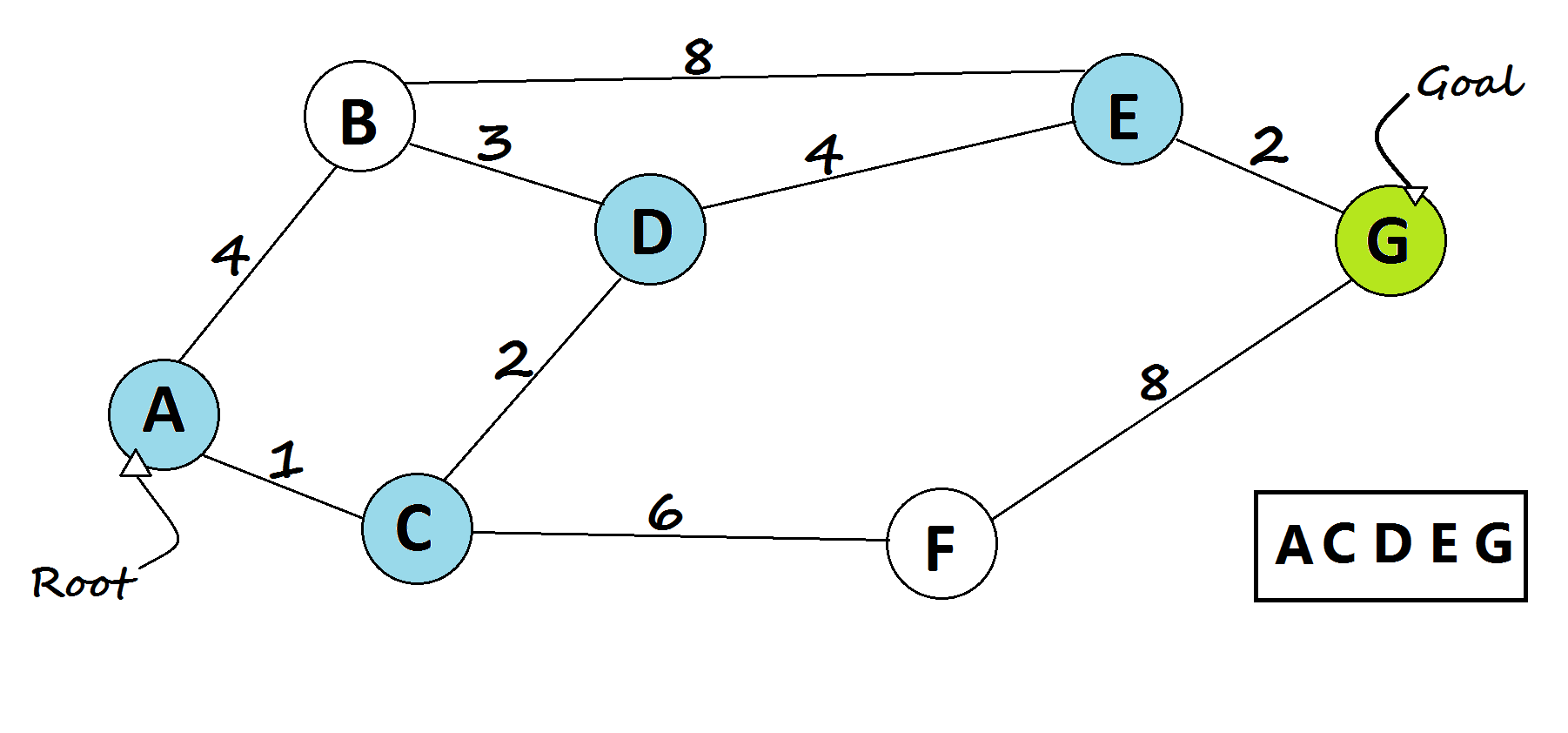
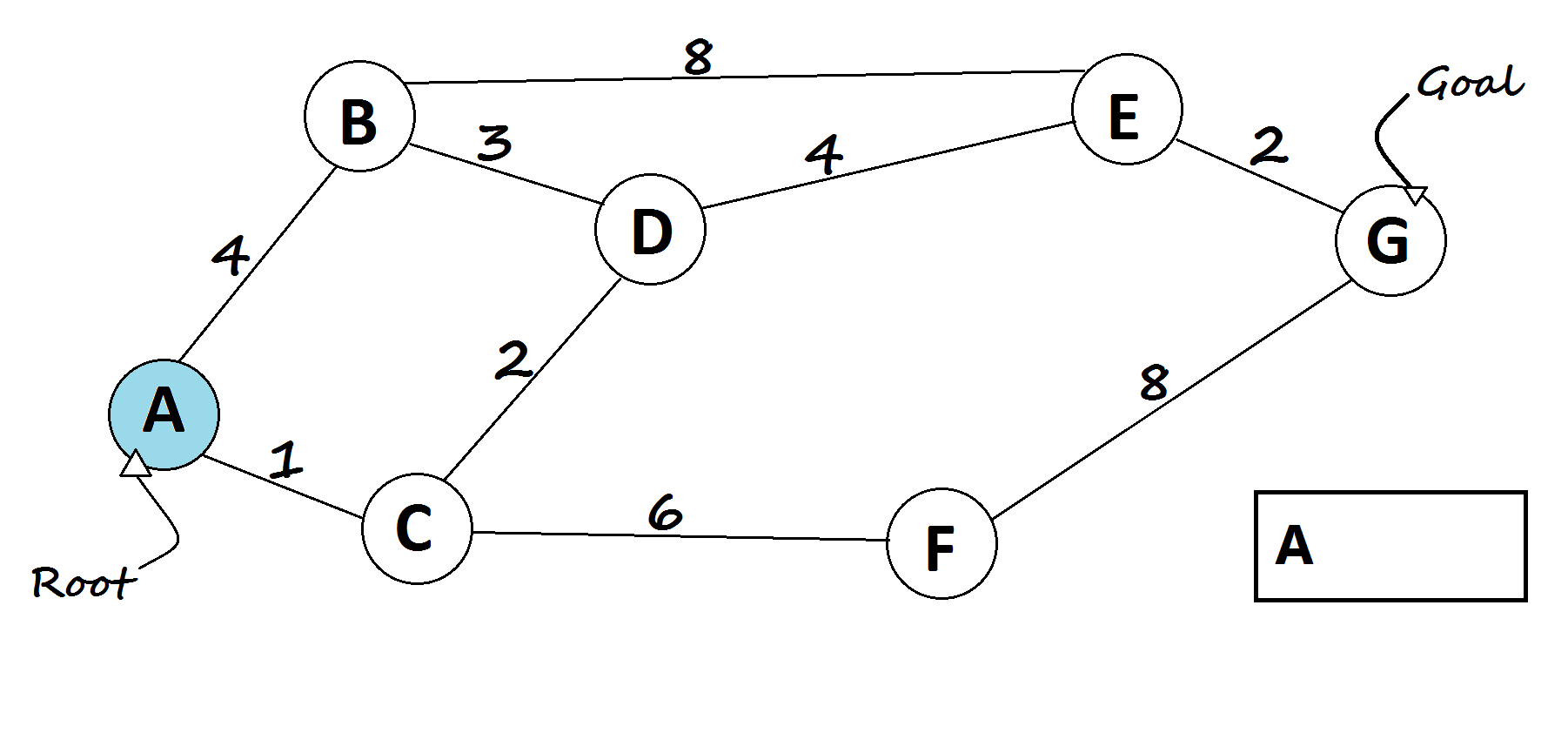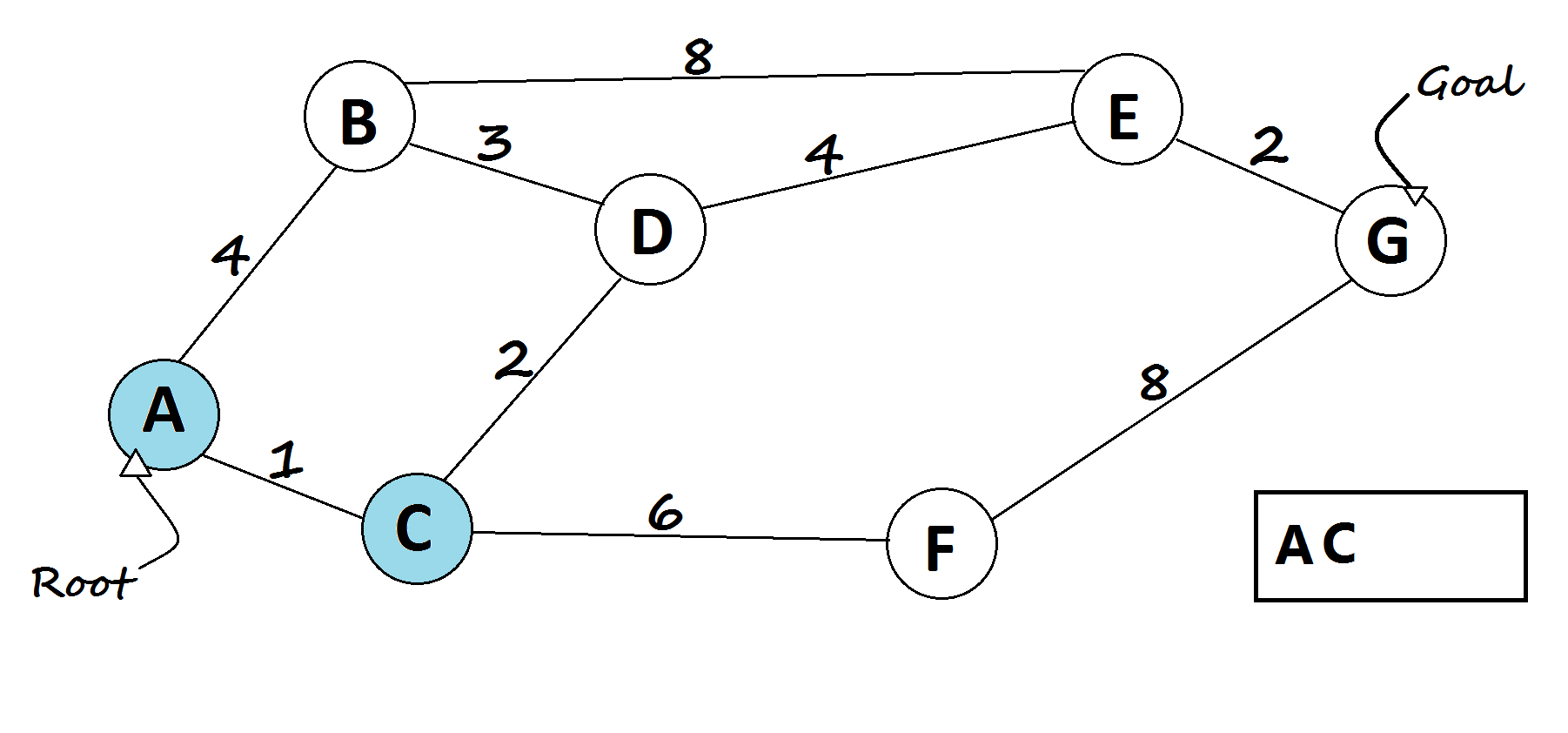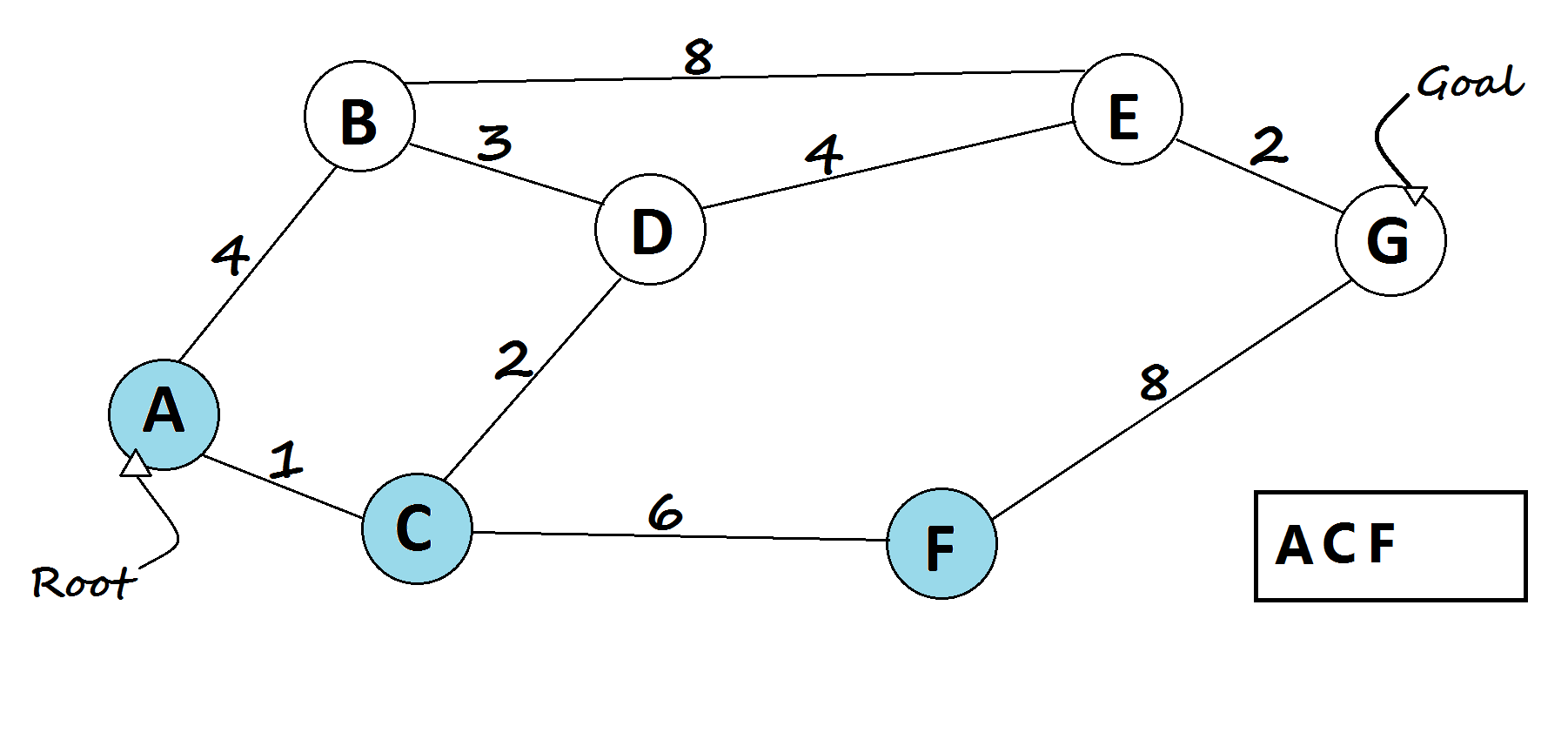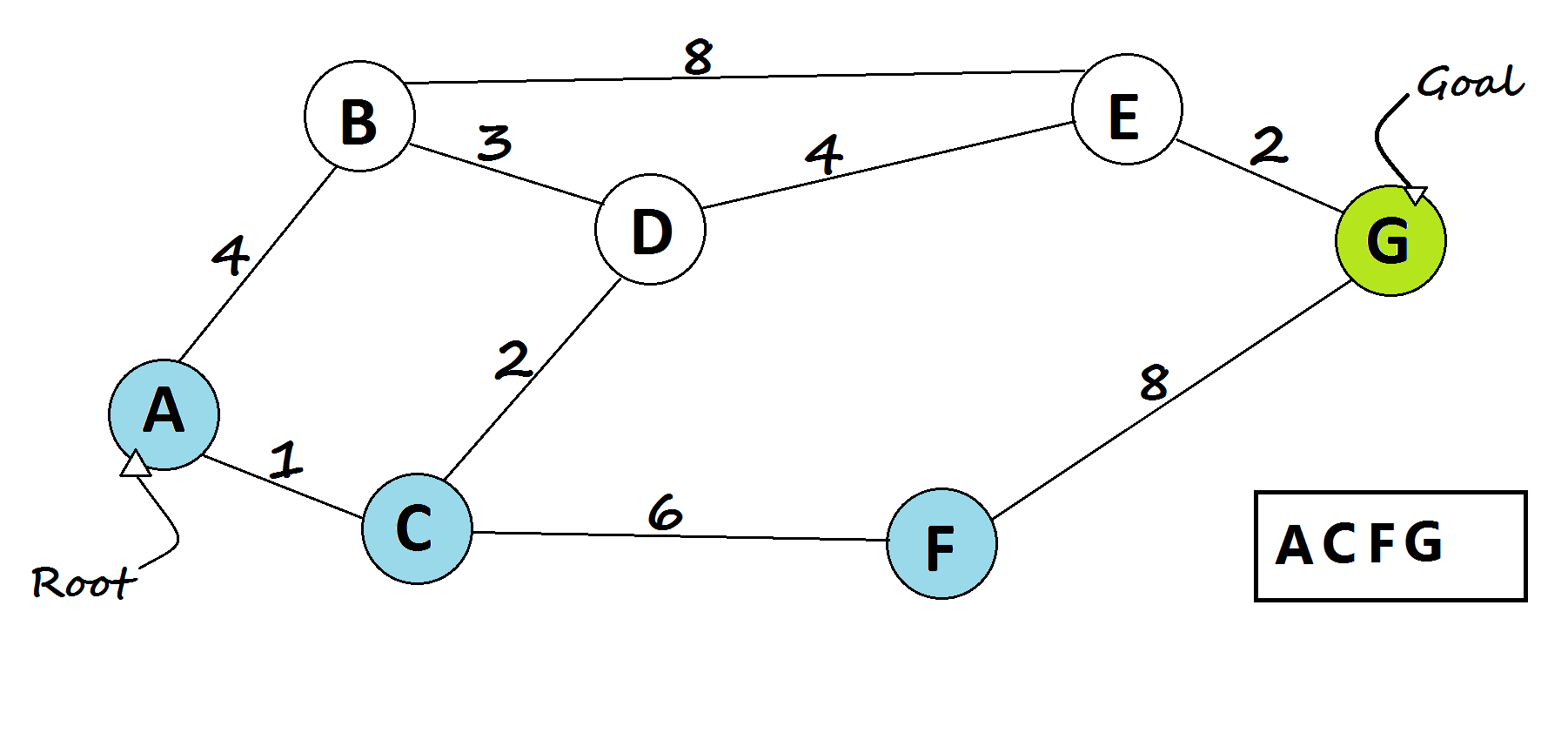
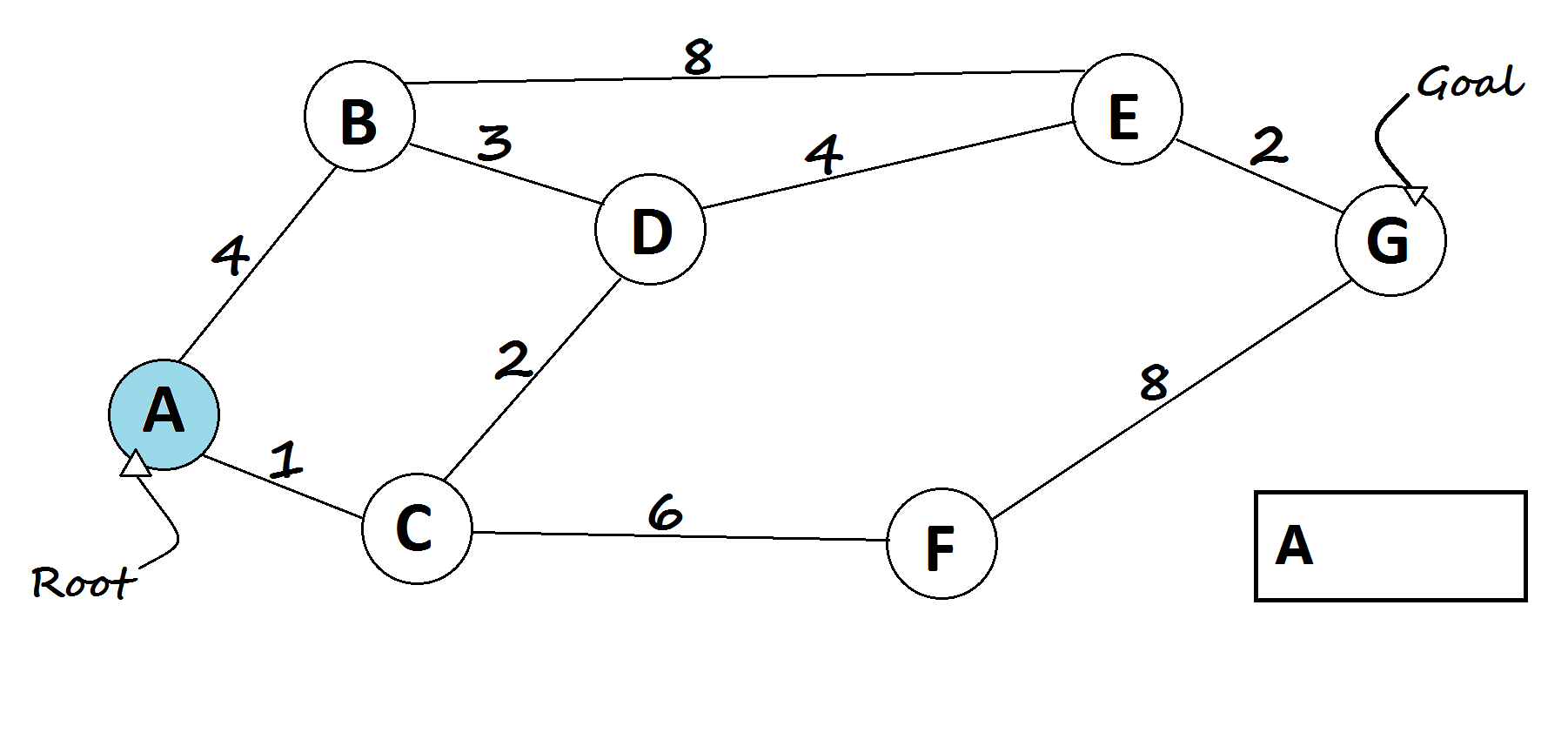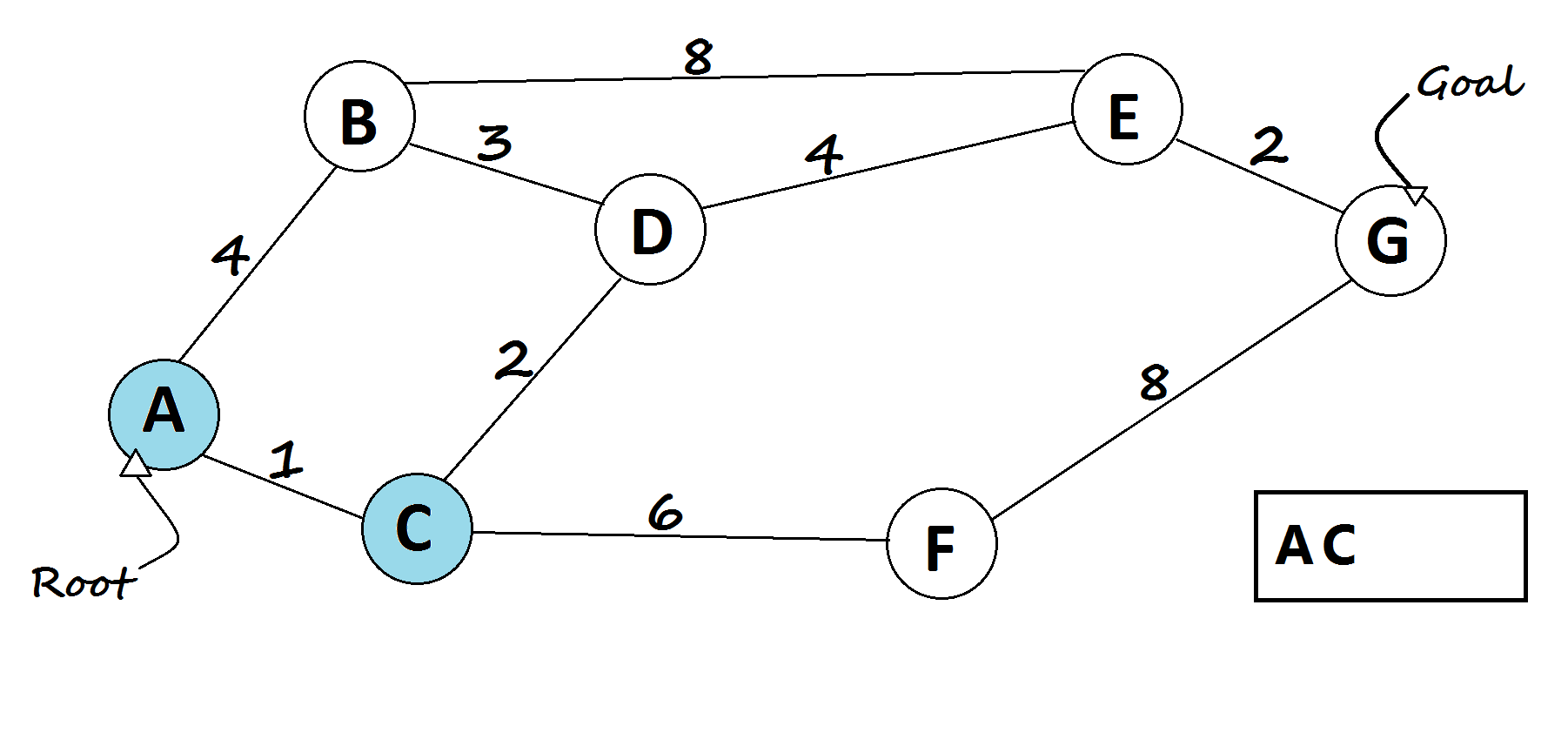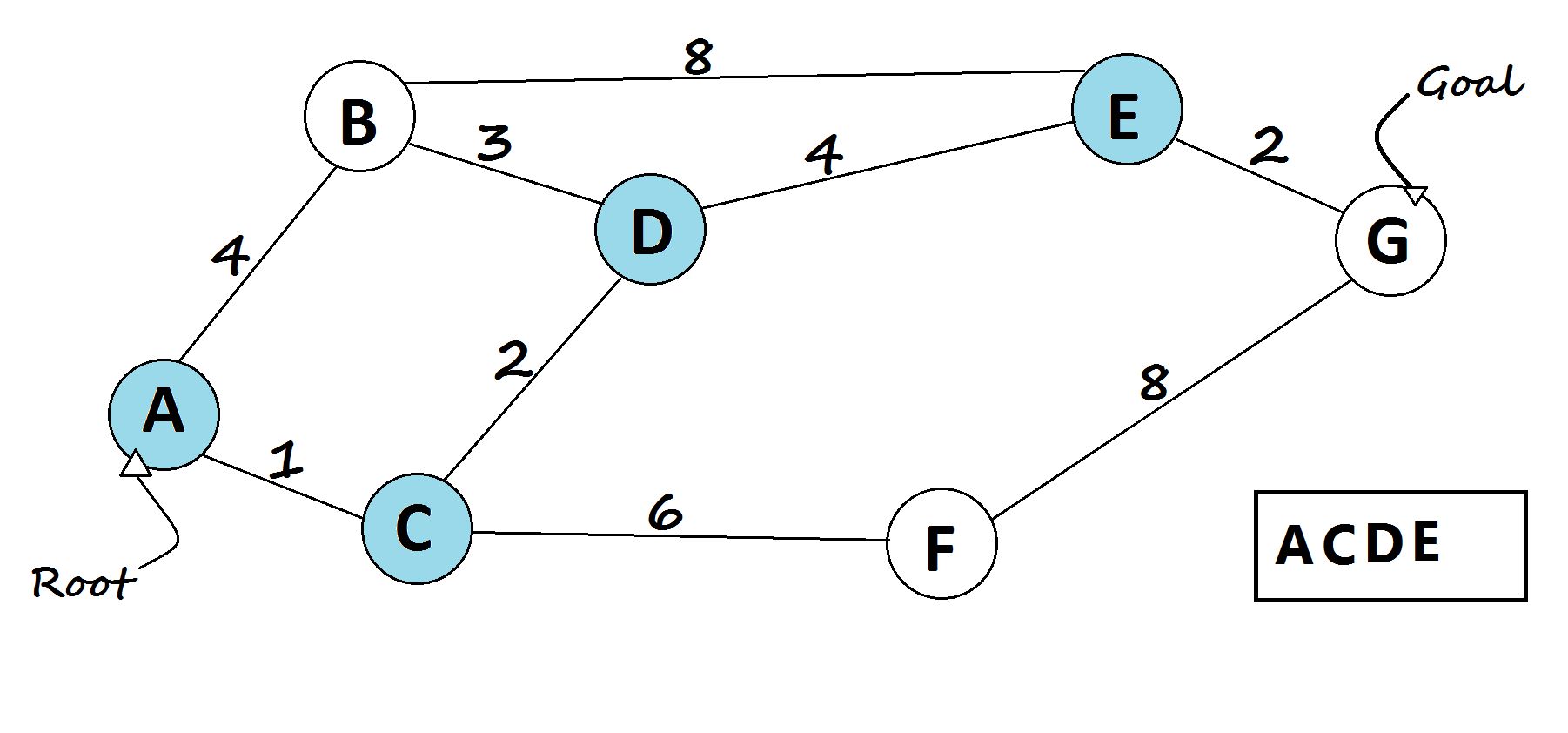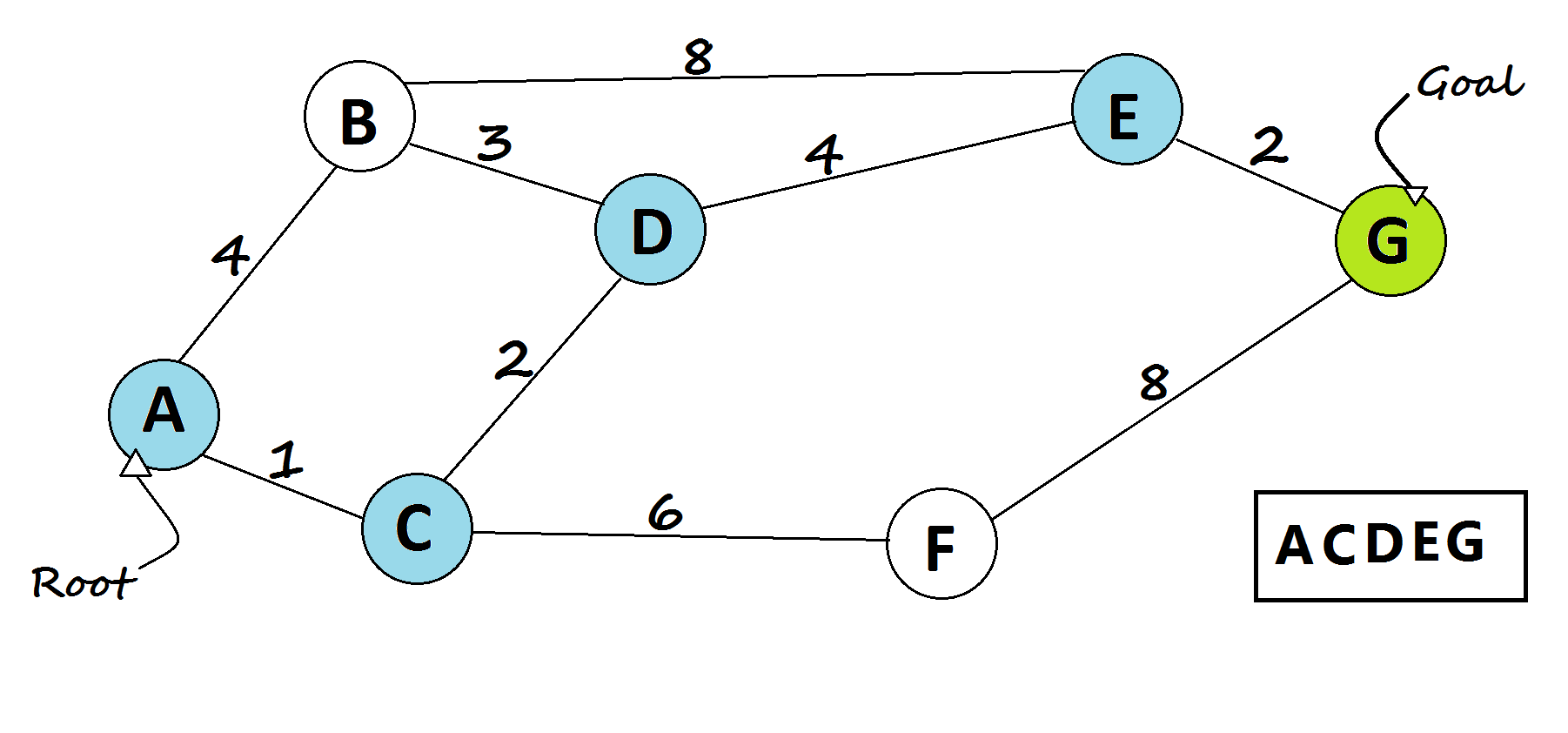
1 — Dijkstra’s shortest path algorithm
2 — Greedy algorithm
3 —Astar algorithm
4 — Depth-First Search algorithm
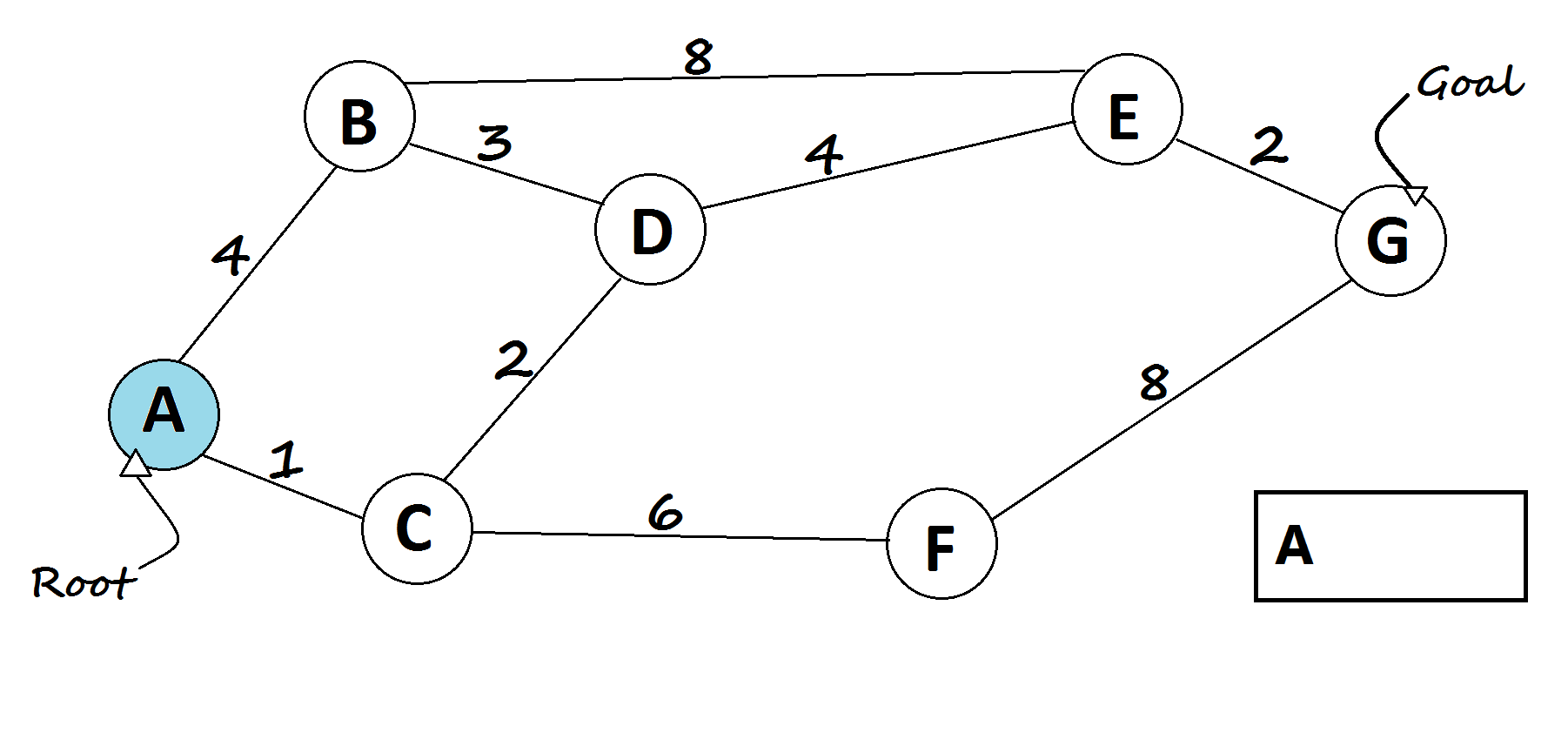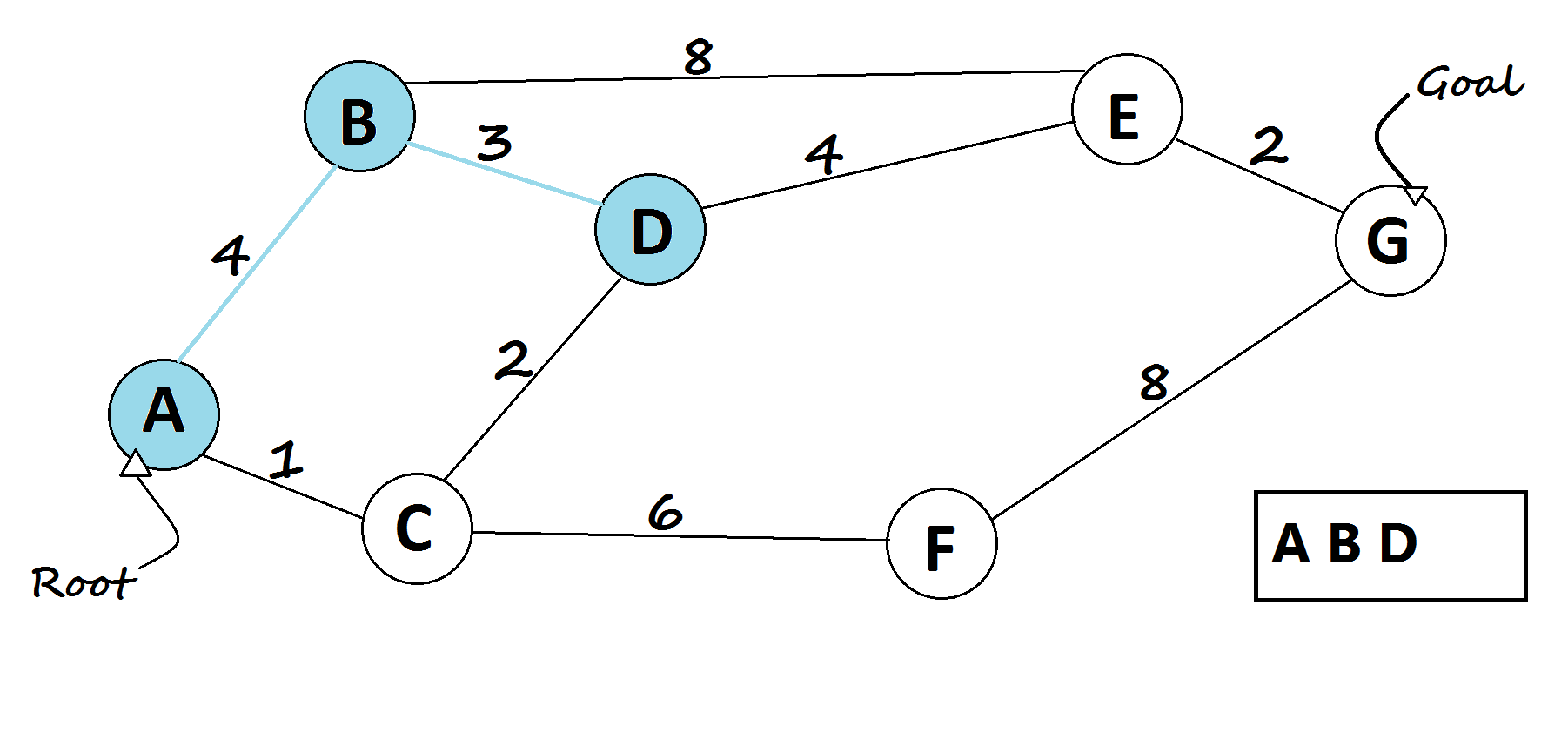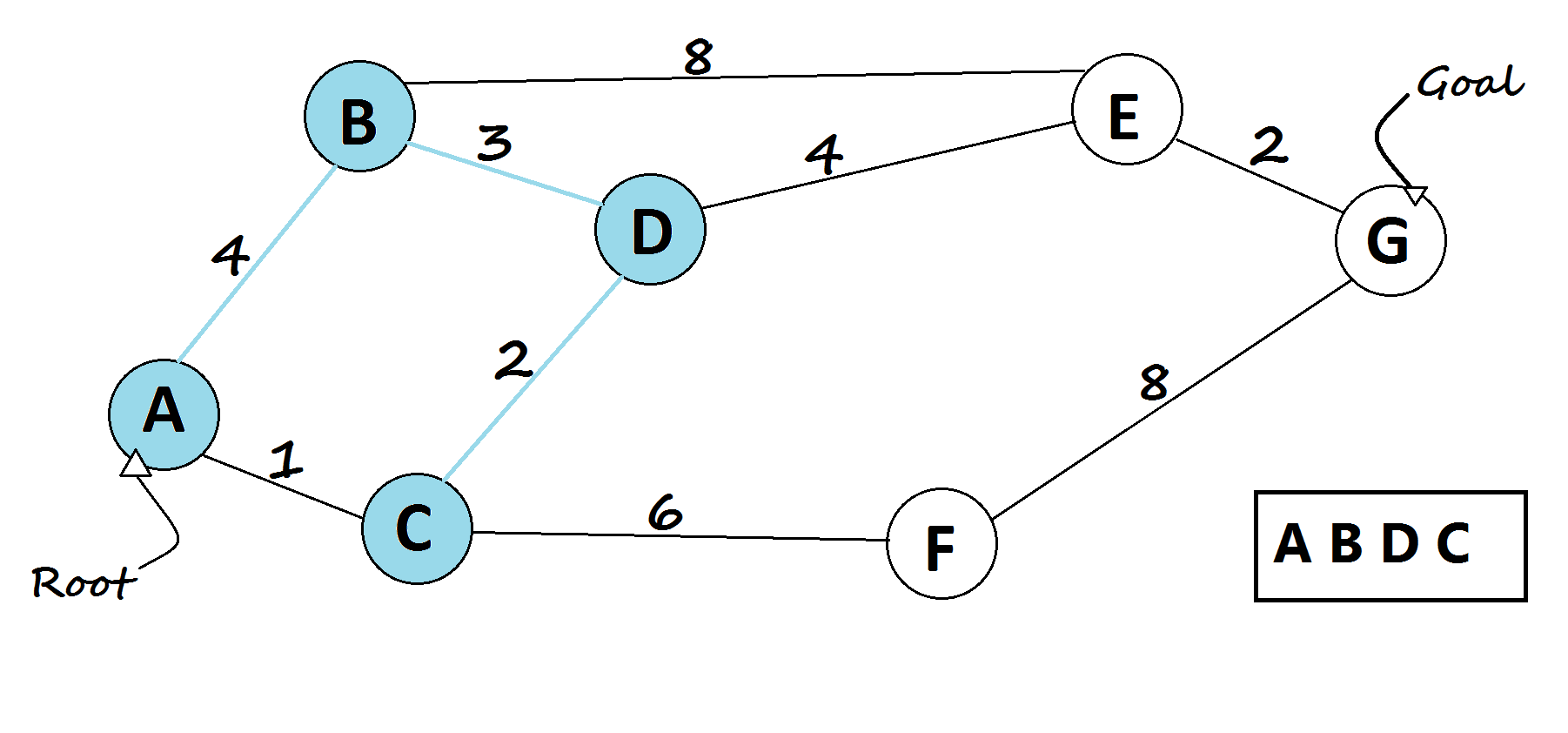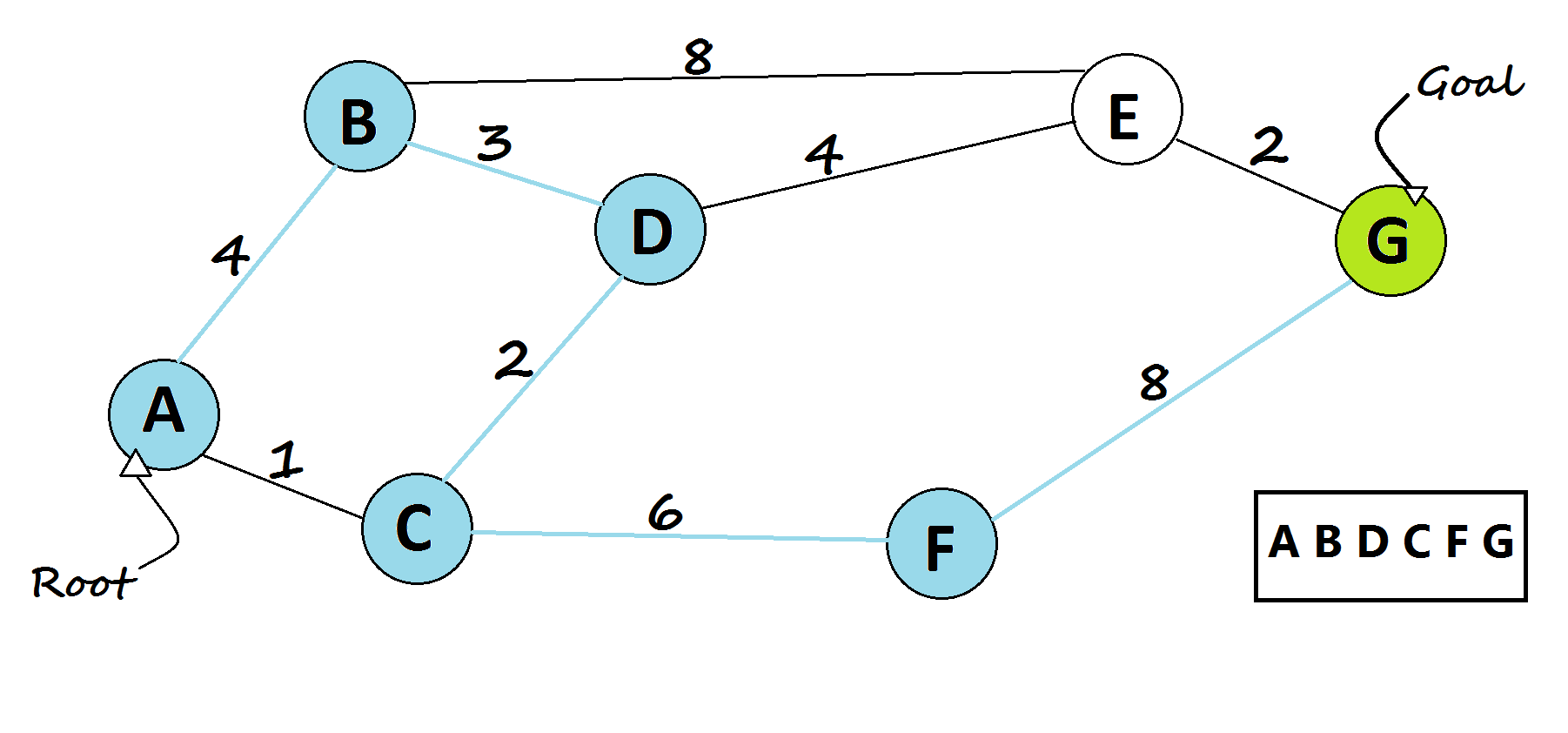
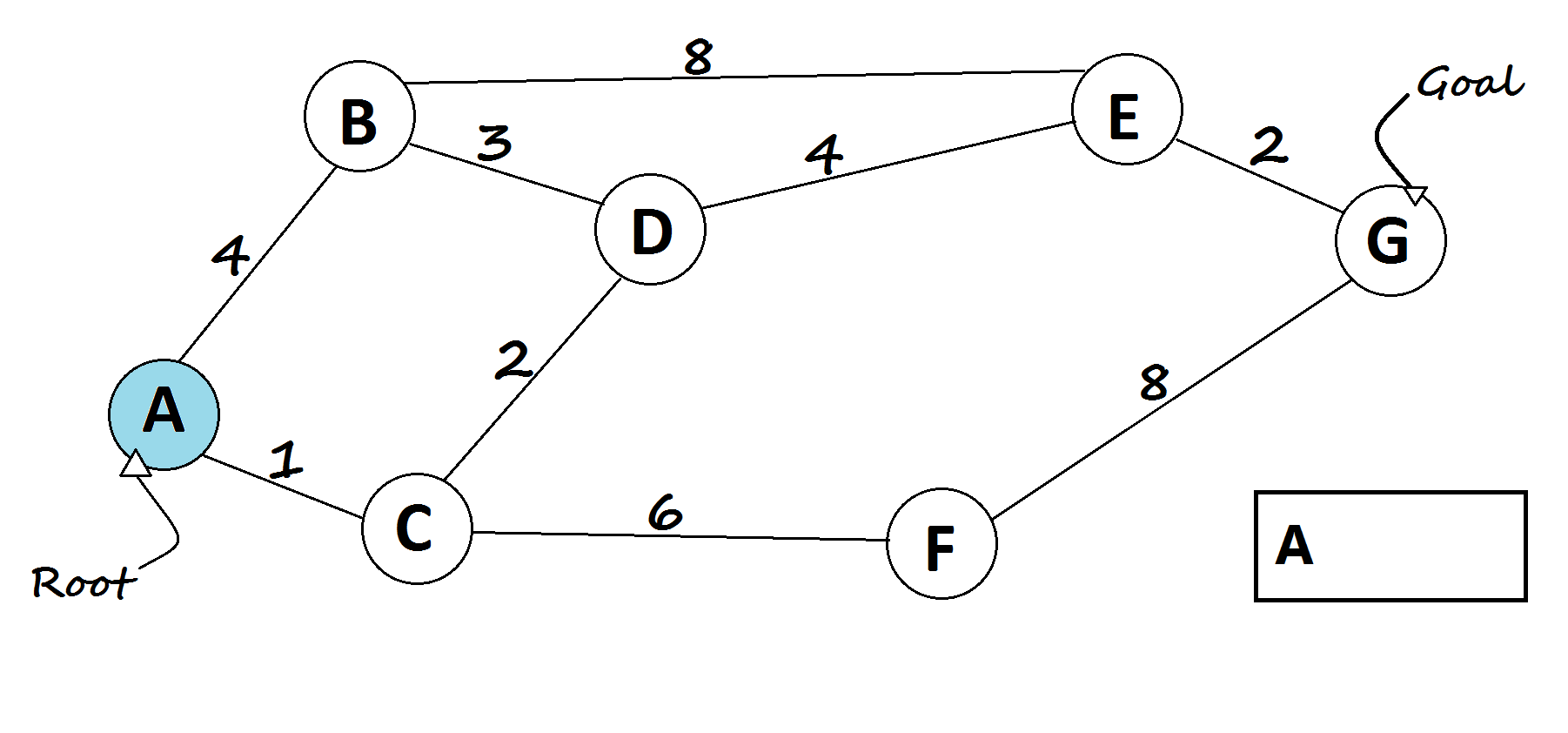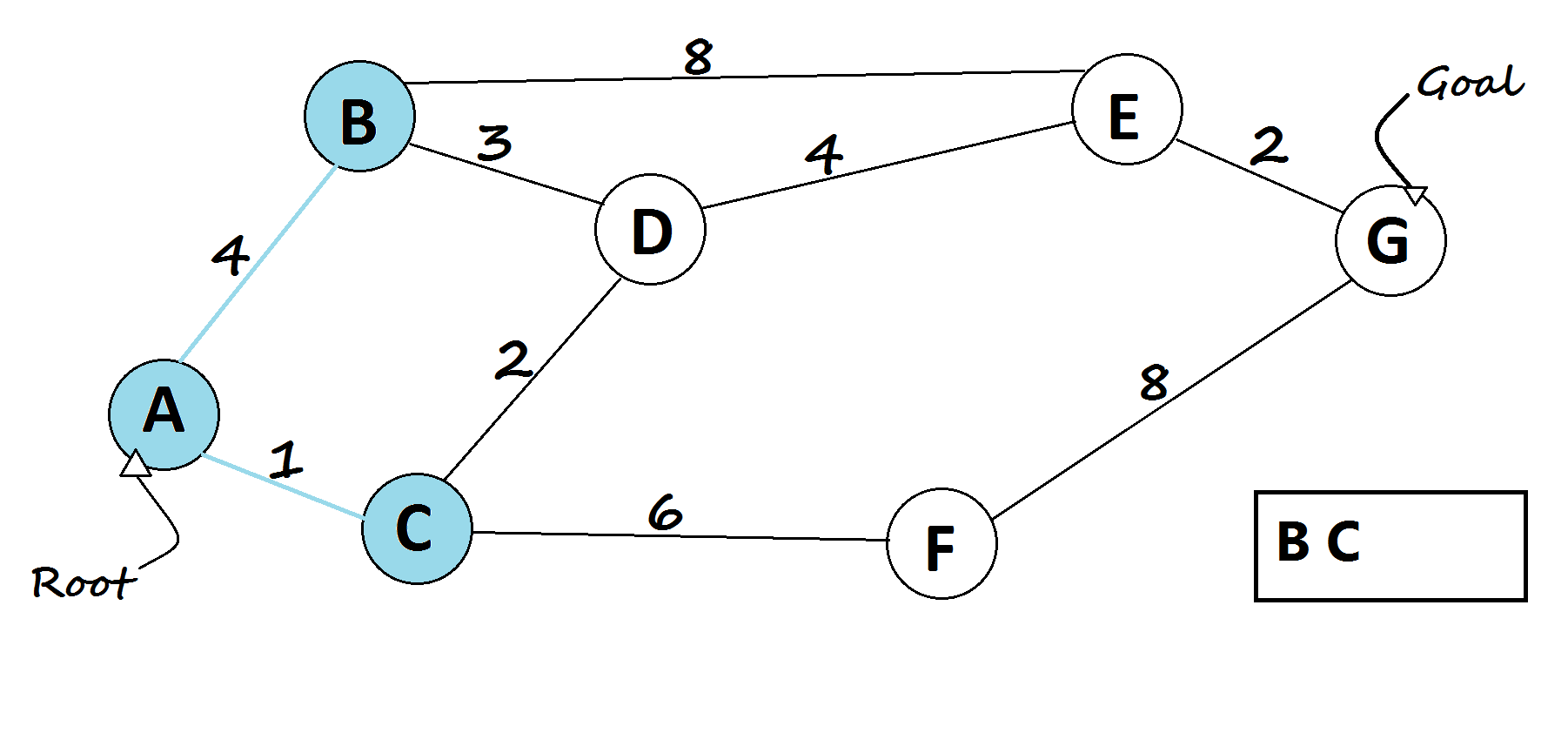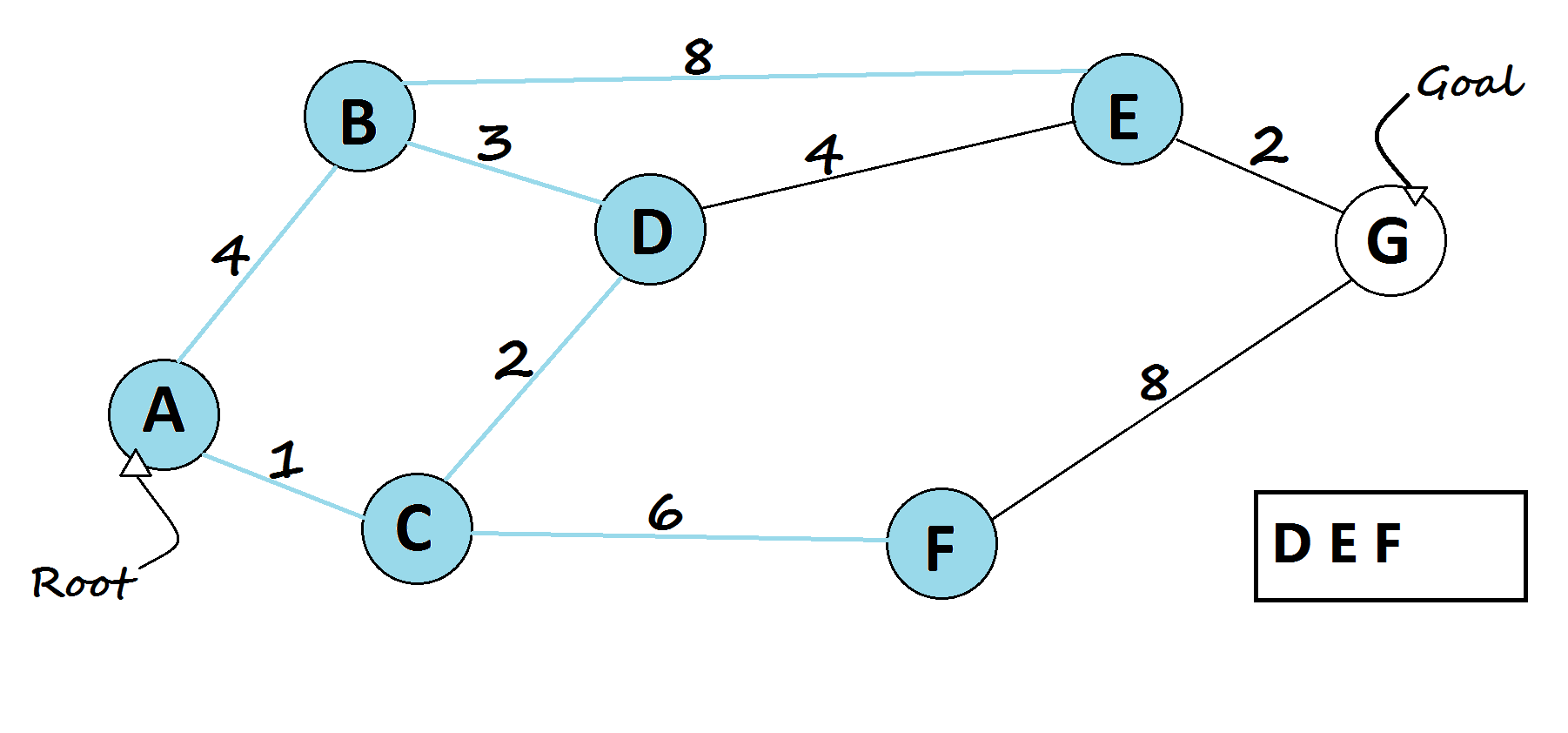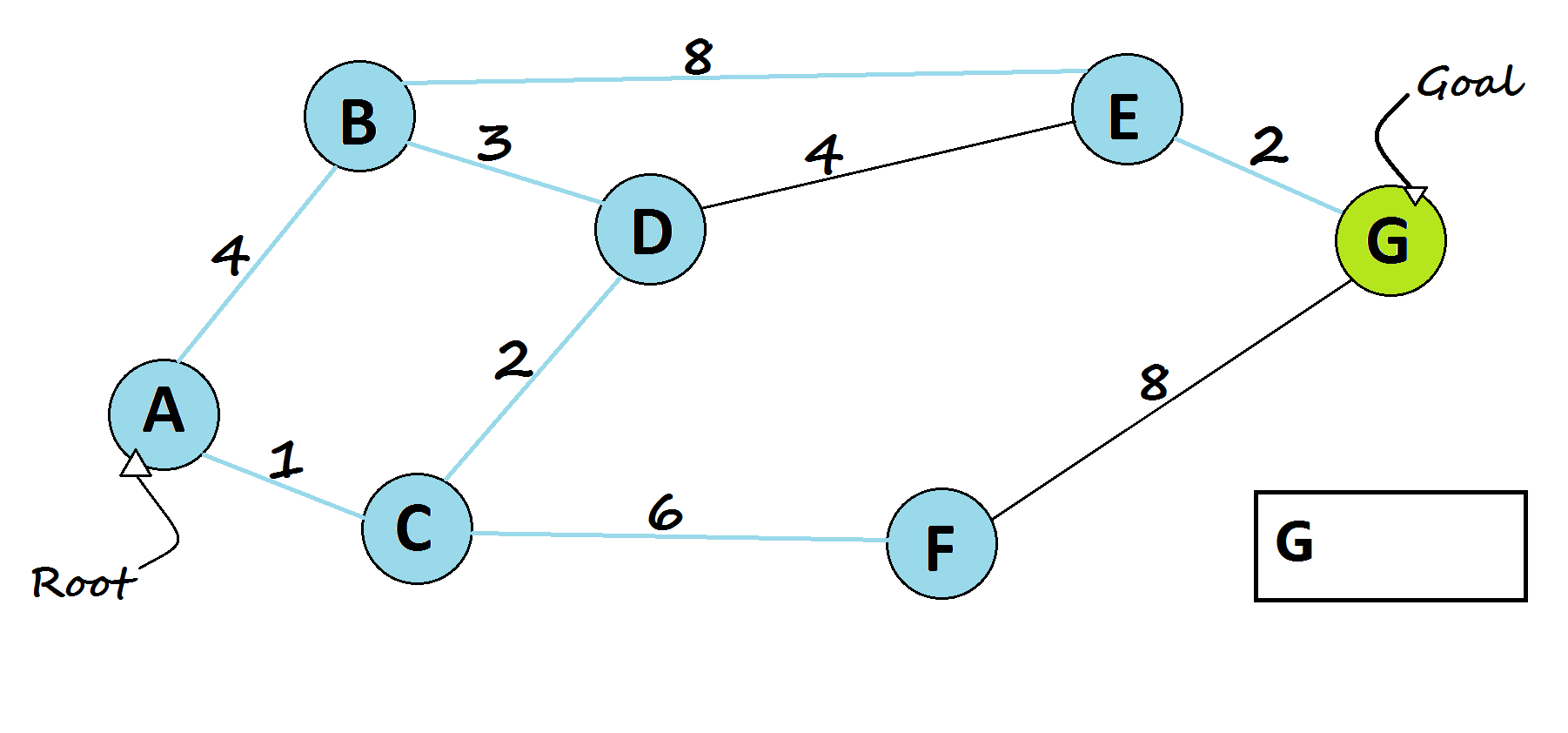
5 — Breadth-First Search algorithm
6 — Bellman-Ford algorithm
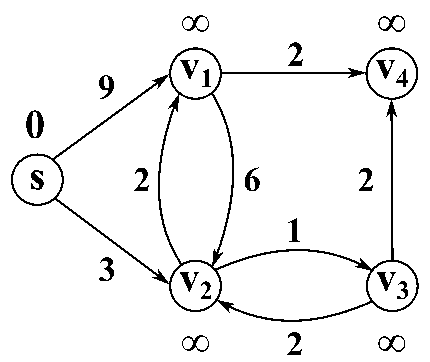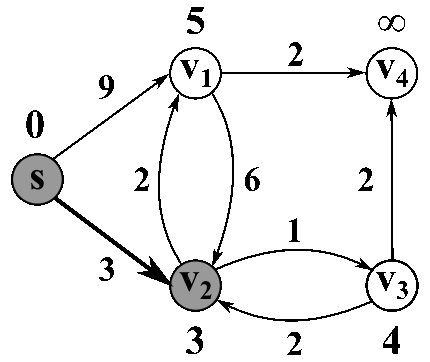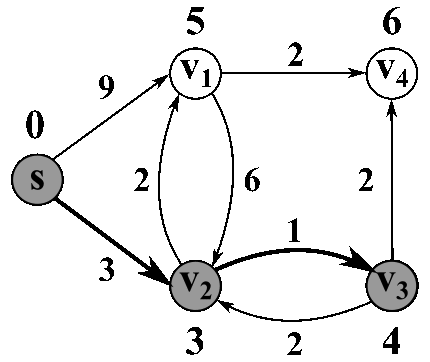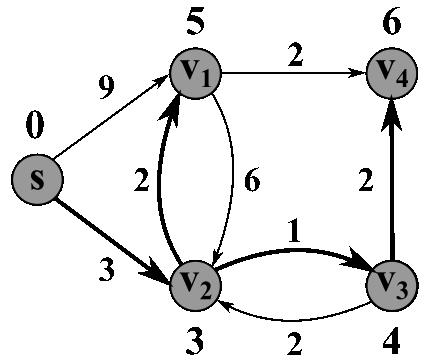
7 — Floyd cycle detection algorithm
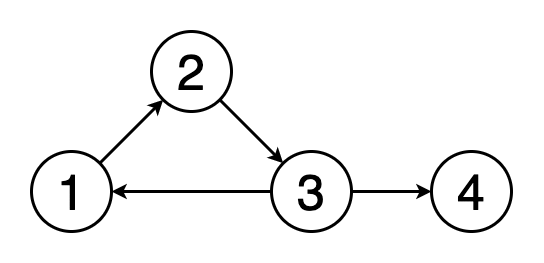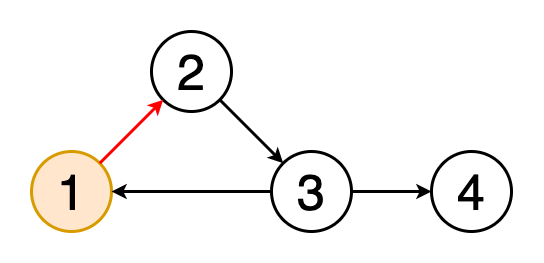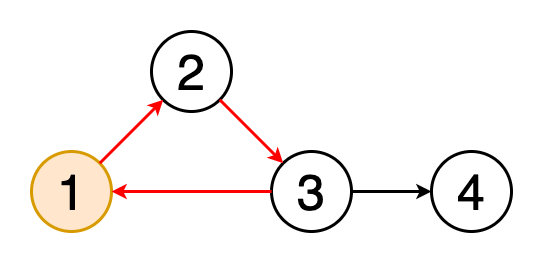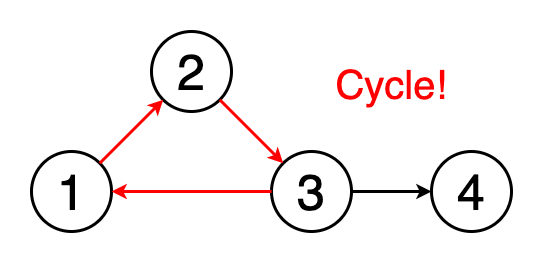
8 — Prim’s algorithm
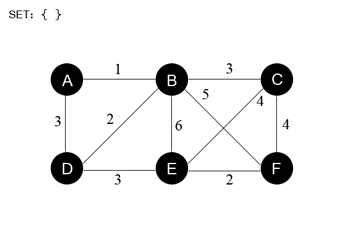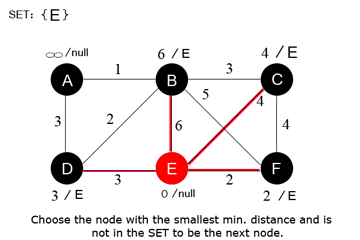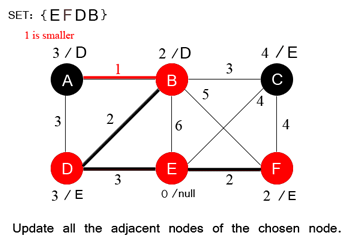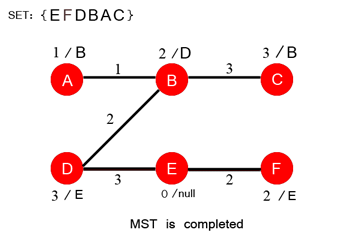
9 —Kahn’s algorithm
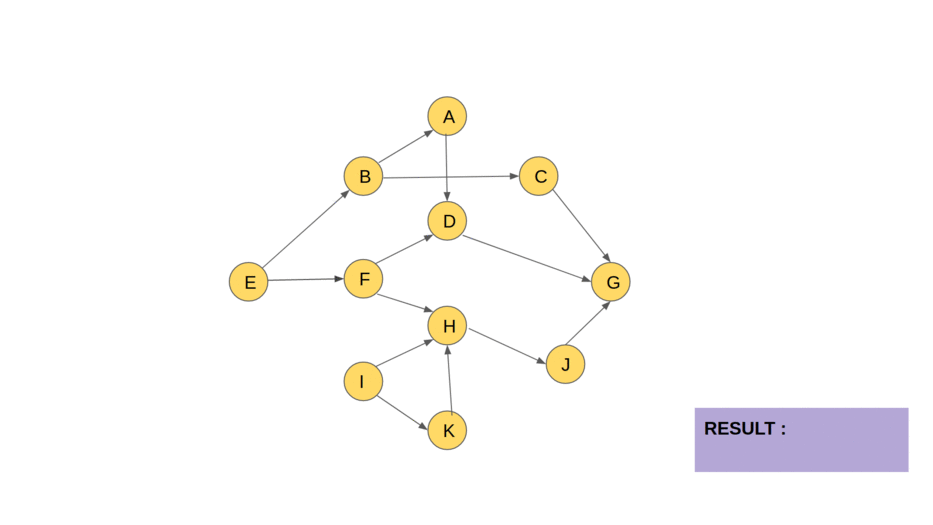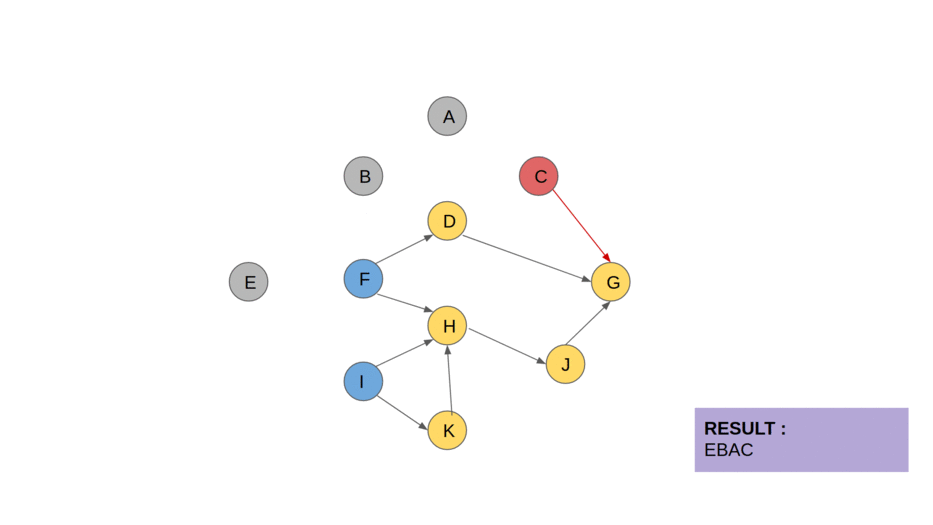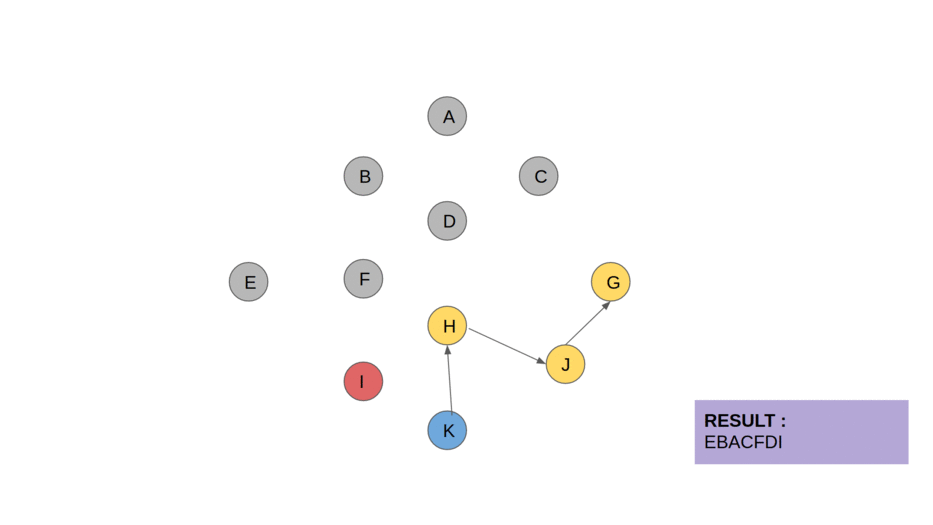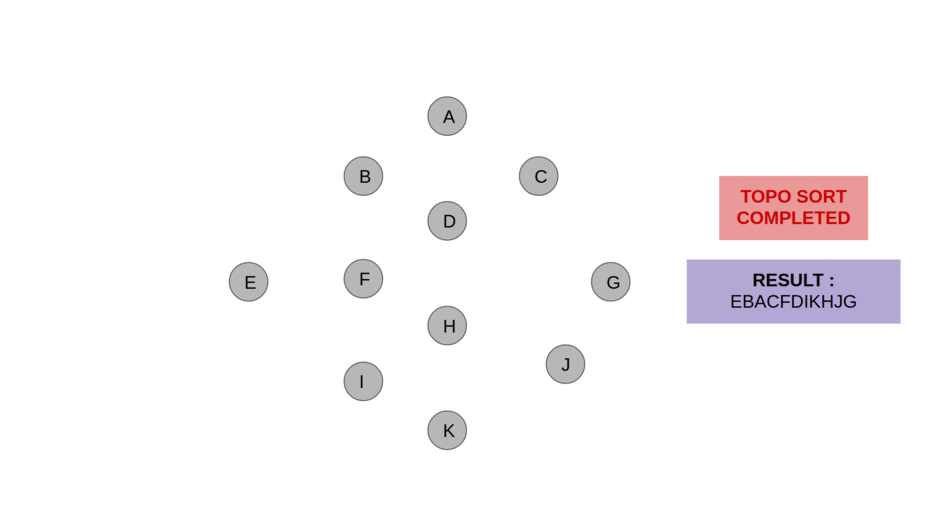
10 — Tarjan’s strongly connected components algorithm
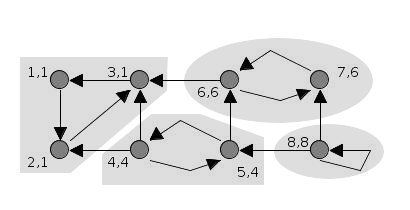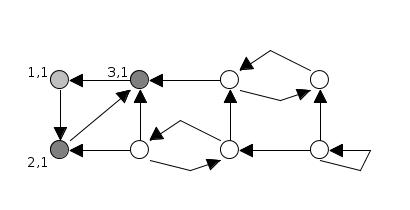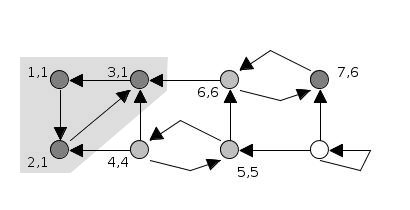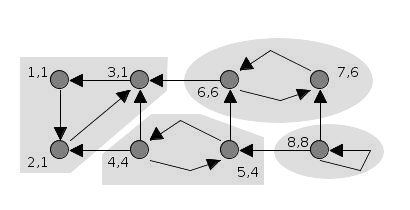
11 — Brent’s algorithm
12 — Kruskal’s algorithm
13 — Kosaraju’s algorithm
14 — Ford-Fulkerson algorithm
15 — Edmonds–Karp algorithm
16 — Dinic’s algorithm
17 — Hopcroft-Karp algorithm
18 — Hungarian algorithm
19 — Blossom algorithm
Time Complexity
The most famous solution for finding the shortest path was first proposed by Dijkstra. Generally, his solution is the most efficient and used in most cases. On average each of N nodes is processed, and for each, all of its neighbors are updated in O(N). Thus the complexity is O(N²).
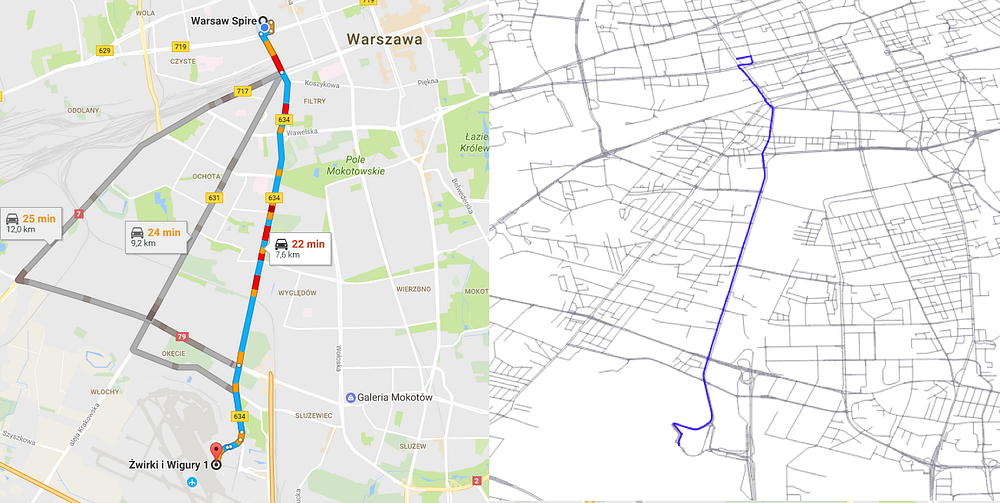
How to reduce the Time Complexity?
Well, let’s discuss it in the next part. In the meantime, try to implement these Graph Algorithms and understand their core concepts.
Hope this can help. Share your thoughts too.
Comments
Post a Comment