Data Structure
As a definition, the data structure is a specific method of organizing data in a computer so that it may be used efficiently.
In this article, we are going to see about the Collection Framework which enables us to implement some important Data Structures available on Java.
Topics covered:
∘ Data Structure
∘ Collection Framework
∘ Class vs Interface
∘ Lists
∘ Set
∘ Map
∘ Difference between List, Set, and Map interface in Java
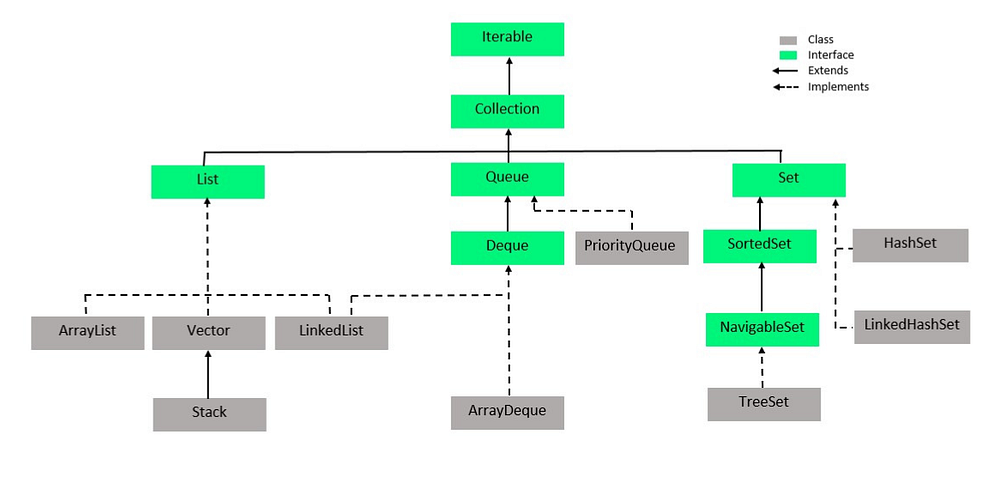
Collection Framework
A Java collection is a grouping of separate objects that are represented as a single entity. Java collections, like data, provide all actions such as searching, sorting, insertion, modification, deletion, and so on. Java Collections is a fairly broad topic, and as a newbie, it might be tough to find your way around. We’ve covered all you need to know to get started with Java Collections.
 |
| Image from https://www.geeksforgeeks.org/how-to-learn-java-collections-a-complete-guide/ |
What exactly is a framework in Java?
- It offers prefabricated architecture.
- It denotes a bundle of classes and interfaces.
- It is entirely optional.
What exactly is the Collection Framework?
The Collection framework is a coherent architecture for storing and manipulating a collection of items.
It has:
- Interfaces and their implementations, i.e., classes
- Algorithm
Class vs Interface
Lists
The Collection interface gives way to the List interface. A list’s components are arranged in sequential order. The user may access a specific element in the list by using the index number; in other words, the user has total control over which element is put where in the list.
ArrayList
The List interface is implemented by the ArrayList class. This class’s objects are dynamic arrays. The ArrayList is a resizable version of the List class. It implements all List methods and accepts all items, even null ones. The capacity of ArrayList objects is initially equal to the size, but it grows dynamically when additional components are added. An ArrayList is unsynchronized, which means it may be accessed by several threads at the same time. In the Operating System, a thread is a unit of sequential flow control that may be processed.
Syntax to create an integer type ArrayList;
ArrayList<Integer> intArrayList = new ArrayList<Integer>();
Set
The Set interface adds to the functionality of the Collection interface. The Set is a structure that represents a set’s mathematical definition. It depicts an unsorted group of elements that prevents us from storing duplicates. In Set, we can only save one null value. HashSet, LinkedHashSet, and TreeSet are all implementations of Set.
Let’s see the implementation of one of the implementations of Set due to a special property which we can see in the comparing part.
TreeSet
The Navigable interface is implemented by the TreeSet class. The TreeSet employs a tree structure to store components and a set to organize them, as the name implies. Natural ordering or order by the Comparator set at the time of building are the two options. Because the TreeSet is unsynchronized, we must synchronize it externally if many threads wish to access it at the same time.
Syntax to create an integer type TreeSet;
TreeSet<Integer> intTreeSet = new TreeSet<Integer>();
Let's see an implementation of TreeSet.
Map
The Map interface is a structure that associates each value with a key. Because one key cannot have multiple mappings, a Map does not allow duplicate items. A Map may be seen in three ways: as a Set of keys, a Set of key-value mappings, or as a Collection of values. The Map interface’s methods are listed below, and any class that implements Map must define these methods.
SortedMap
The SortedMap interface adds the need for a total order of keys to the Map interface. Depending on the constructor used, the keys are either sorted by natural ordering or by a Comparator given at the time of creation. The keys must all be comparable.
TreeMap
The SortedMap interface is implemented by the TreeMap class. The TreeMap class stores data in a red-black tree structure and orders the components using a map. Every element is a pair of keys and values. For fundamental operations, this solution guarantees a log(n) time cost.
Syntax to create a String type TreeMap;
TreeMap<Integer, String> treeMap = new TreeMap<Integer, String>();
Difference between List, Set, and Map interface in Java
1 — Ordering
List — In Java, a list is an ordered sequence whose entries are accessed by an index.
Set — In Java, a set is a unique collection of items that can be sorted or unordered depending on the implementation. HashSet implementations, for example, are unordered, LinkedHashSet implementations are ordered, and TreeSet implementations are ordered by natural order or given comparator.
Map — In Java, a map represents the key-value mapping. Map’s ordering is likewise implementation-dependent. The TreeMap class, for example, is ordered, but the HashMap class is not.
2 — Duplicates
List — It is possible for elements in a list to be duplicated.
Set — Only distinct elements make up a set.
Map — A Map does not allow duplicate keys, which means that each key can only map to one value.
3 — Null values
List — There can be any number of null values in a list.
Set — There can only be one null element in a set.
Map — Although null may be used as both a key and a value in a Map, certain implementations do not allow null keys or values.
4 — Implementing classes
List — ArrayList and LinkedList are two of the most common List interface implementation classes.
Set — HashSet, TreeSet, and LinkedHashSet are examples of set interfaces.
Map — The HashMap, TreeMap, and LinkedHashMap classes are available through the Map interface.
5 — When to use List, Set, and Map?
List — When the insertion order of elements must be maintained, a List can be utilized.
List — When the insertion order of elements must be maintained, a List can be utilized.
Set — If we need to keep a collection free of duplicates, we may use a set.
Map — When the data involves key-value pairs and quick retrieval of a value based on a key is required, use a map.
6 — Index and elements
List — The get() function in the list may be used to retrieve an element at a certain index.
Set — The get method in Set does not return the elements at a specified index.
Map — The get method in the map does not return the entries at a specified index.
7 — Iterator
List — Listlterator is used to traverse the list items.
List — Listlterator is used to traverse the list items.
Set — Iterator is a tool for traversing a set of items.
Map — Through the use of a keyset, a value, and an entry set.
You may encounter questions during your interview as well. These are very basics in Data Structure. Make sure you are aware of all these things.
I hope this can help you. Share your thoughts too.
Comments
Post a Comment